V8 JIT 基础¶
V8 采用分层执行模型。JavaScript 源码首先被编译为 Ignition bytecode,随后根据函数的执行热点和运行时反馈,逐步进入更高层级的编译管线。
JavaScript source -> Ignition bytecode -> Sparkplug -> Maglev -> TurboFan
1. Ignition:解释器¶
Ignition 是 V8 的解释器。它将 JavaScript 函数编译为紧凑的 bytecode,并负责执行这些 bytecode。与直接生成基线机器码相比,bytecode 体积更小,启动成本更低,也更适合作为后续优化阶段的输入。
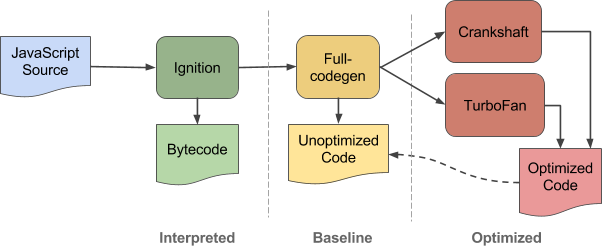
在这一阶段,V8 一边执行 bytecode,一边收集运行时反馈。对象形状、属性访问模式和操作数类型等信息,会被后续编译器用于生成更专门化的代码。调试时,--print-bytecode 主要对应这一层。
2. Sparkplug:非优化基线编译器¶
Sparkplug 是 V8 的 non-optimizing JavaScript compiler。它位于 Ignition 和 TurboFan 之间,负责将 bytecode 快速编译为与解释执行语义等价的机器码。Sparkplug 的设计目标不是进行复杂优化,而是尽可能快地消除解释器固有的开销,例如 bytecode decoding 和 dispatch overhead。
Sparkplug 仍然以 Ignition bytecode 作为输入,并尽量复用现有 builtin 和调用约定。它生成机器码的速度很快,因此适合较早介入执行管线,在不等待顶层优化编译完成的情况下提供稳定的性能收益。
3. Maglev:中层优化编译器¶
Maglev 是 V8 的 fast optimizing compiler,位于 Sparkplug 和 TurboFan 之间。它的目标是在编译速度和代码质量之间取得中间位置,即生成明显优于 Sparkplug 的代码,同时保持远低于 TurboFan 的编译成本。

Maglev 直接基于 bytecode 和运行时反馈构建中间表示,并根据已经观察到的类型和对象形状生成专门化代码。当这些假设在运行时不再成立时,代码会触发 deoptimization 并回退到更低层级的执行路径。对分析 JIT 行为而言,Maglev 是连接 baseline 编译和 peak-performance optimization 的关键一层。
4. TurboFan:顶层优化编译器¶
TurboFan 是 V8 的 optimizing compiler,目标是峰值执行性能。它利用 bytecode 和运行时反馈生成高度专门化、通常带有投机性质的机器码,因此编译成本最高,但生成代码的性能上限也最高。
在这一层,V8 会更积极地利用类型信息、对象形状信息以及控制流信息进行优化。相应地,错误类型推断、缺失检查、错误去优化路径等问题,也更容易在这一层暴露。调试时,--trace-opt、--trace-deopt 和 --trace-turbo 主要用于观察这一阶段的编译与回退行为。
5. Turboshaft 和 TurboFan 的关系¶
TurboFan / Turboshaft 经常被并列提及,但两者并不表示两层独立的执行 tier。按照执行分层理解,顶层优化编译器仍然是 TurboFan;而 Turboshaft 更接近于 V8 近年来引入的内部 IR 和编译基础设施,用于逐步替换 TurboFan 的部分传统实现。因此,Turboshaft 更适合被理解为顶层优化管线内部的演进,而不是新增的一层 JIT。
6. 调试时的对应关系¶
| 层级 | 关注点 | 常用 flag |
|---|---|---|
| Ignition | bytecode、寄存器/累加器语义 | --print-bytecode |
| Sparkplug | baseline code 是否生成 | 具体 flag 随版本变化,通常先看 --help |
| Maglev | 中层优化是否介入、是否发生 deopt | --trace-opt、部分版本提供 Maglev trace flag |
| TurboFan | 优化图、机器码、deopt 点 | --trace-opt --trace-deopt --trace-turbo |